
“Oh My God, inflation is on the way and you’d better put your money in Gold Bullion and Gold Currencies (Coins).”
That is the cry of many today. To understand the ramifications of inflation let’s take a look at the American Dollar and how it has shrunk in purchasing power since the early 1900s … but I warn you the inflation being talked about today is nothing new and nothing you should fear so much that it causes you to put all your money in Gold.

As you can plainly see, had you had a dollar in 1913 you would be able to purchase 30 Hershey’s chocolate bars. Today you would get a small coffee and McDonalds for the same dollar. And, you may get 2/3rds of a Hershey Bar.
Now there are those out there that will tell you all this occurred because in 1933 Congress voted to take our currency in America off the “gold standard” … which required us to have in storage enough gold to back every dollar we printed. My comment to that is what happened from 1913 to 1920 (when we had a gold standard) that caused the dollar to go down from having the ability to purchase $26.14 in goods to just about $12.50 in goods in a period of just 7 years? During this time, of course, the value of gold was set by the government for about $35 an ounce and it had traded at that value for many years.
Yes, when the dollar lost the backing of Gold it did start to depreciate in value … but I contend that inflation did more to destroy the value of the dollar than no longer having a gold standard did.
So, what is inflation?
Much of the next few paragraphs comes from: https://www.investopedia.com/ask/answers/111314/what-causes-inflation-and-does-anyone-gain-it.asp However, I have added my words in some of them.
Inflation is a measure of the rate of rising prices of goods and services in an economy. It can occur when prices rise due to increases in production costs, such as raw material and wages. As wages increase so will prices, eventually. As the cost to mine, or acquire, raw materials increase, so will the products cost that are produced from those raw materials.
A surge in demand for products and services can cause inflation as well – even if the cost to produce them does not increase. Why is this? People want the product so badly that they are willing to pay more for it.
Inflation can occur in nearly any product or service, including need-based expenses such as housing, food, medical care, and utilities, as well as want-based expenses, such as cosmetics, automobiles, and jewelry. Once inflation becomes prevalent throughout an economy, the expectation of further inflation becomes an overriding concern in the consciousness of consumers and businesses alike. It’s like a self-fulfilling prophecy. If you think it is going to get bad … it usually does.
There are basically two types of inflation …
Cost-push inflation occurs when prices increase due to increases in production costs, such as raw materials and wages. The demand for goods is unchanged while the supply of goods declines due to the higher costs of production. As a result, the added costs of production are passed onto consumers in the form of higher prices for the finished goods.
One of the signs of possible cost-push inflation can be seen in rising commodity prices such as oil and metals since they’re major production inputs. For example, if the price of copper rises, companies that use copper to make their products might increase the prices of their goods. If the demand for the product is independent of the demand for copper, the business will pass on the higher costs of raw materials to consumers. The result is higher prices for consumers without any change in demand for the products consumed.
Wages also affect the cost of production and are typically the single biggest expense for businesses. When the economy is performing well, and the unemployment rate is low, shortages in labor or workers can occur. Companies, in turn, increase wages to attract qualified candidates, causing production costs to rise for the company. If the company raises prices due to the rise in employee wages, cost-push inflation occurs.
Demand-pull inflation can be caused by strong consumer demand for a product or service. When there’s a surge in demand for a wide breadth of goods across an economy, their prices tend to increase. While this is not often a concern for short-term imbalances of supply and demand, sustained demand can reverberate in the economy and raise costs for other goods; the result is demand-pull inflation.
Consumer confidence tends to be high when unemployment is low, and wages are rising—leading to more spending. Economic expansion has a direct impact on the level of consumer spending in an economy, which can lead to a high demand for products and services.
As the demand for a particular good or service increases, the available supply decreases. When fewer items are available, consumers are willing to pay more to obtain the item—as outlined in the economic principle of supply and demand. The result is higher prices due to demand-pull inflation.
Companies also play a role in inflation, especially if they manufacture popular products. A company can raise prices simply because consumers are willing to pay the increased amount. Corporations also raise prices freely when the item for sale is something consumers need for everyday existence, such as oil and gas. However, it’s the demand from consumers that provides the corporations with the leverage to raise prices.
Other things that cause inflation:
Natural disasters can also drive prices higher. For example, if a hurricane destroys a crop such as corn, prices can rise across the economy since corn is used in many products. This could be considered inflationary concerns that are caused by an “Act of God.”
Now most inflation is a natural occurrence in capitalistic society and not something we should fear. It is Natural and will always be with us.
There is another form of inflation that is what I call “Man-made Inflation.” This is not necessarily caused by supply and demand that comes naturally or an “Act of God.”
What we have going on in America today would be considered – in my opinion – Manufactured Inflation (or man-made inflation).
For example, we have over 100 ships off the coast of California (and thousands worldwide) that cannot unload the products they have on board. They are just sitting out in the ocean with much of it (food for example) ruining. The number of ships coming in is growing as each day passes.

What is causing all this blockage which in turn is causing rapid inflation?
- There are not enough workers in the docks to unload the ships quickly enough.
- There are not enough workers in the warehouses to unload the containers if they need to be unloaded and stored until the truck drivers can pick them up.
- There are not enough truck drivers to be able to move the freight as quickly as it needs to be moved across the country.
- More than a half million shipping containers on ports not being unloaded due to ports operating at only 60% of capacity.
- Most ports operate 40 hours per week 5 days per week even though they should be operating 24 hours per day 7 days per week. This is what the government is currently calling for – but how can a government mandate what a private company should do?
- A struggle to hire enough workers has had a tremendous impact on the transportation industry nationwide, causing headaches at ports, warehouses, railways, and trucking. Many companies have fewer workers than before the so-called pandemic but face significantly more work due to the boom in demand for goods since the so-called pandemic started.
Most all of these problems have been caused by man making poor decisions. The Biden Administration saw this occurring long before it did, and did nothing to improve it while doing a lot to make it worse – for example – paying people more to stay home than they can make at work.
We actually have people in government now saying Americans should not spend as much money as they do … while at the same time paying Americans more money to stay at home and not look for jobs. If you don’t want us spending money … quit giving us money to spend and make us go out and earn it. Now there is even a shortage of chassis needed to take all the containers by truck to destinations where they need to go.
One other fact that effects mostly California is the stupid laws that went into force in 2020.
- Trucks that are 11 years old or older are not allowed in ports of California to pick up goods.
- Trucks driven by “Owner/operators” or “Independent Contractors” are not allowed to run in California. California requires all truck drivers to be an employee collecting a W2 at the end of the year.
This is from Insider.com:
https://www.businessinsider.com/shipping-containers-stuck-california-ports-combat-shortages-2021-9
A struggle to hire enough workers has had a tremendous impact on the transportation industry nationwide, causing headaches at ports, warehouses, railways, and trucking. Many companies have fewer workers than before the pandemic but face significantly more work due to the boom in demand for goods since the pandemic started.
The shipping delays have made it more difficult for truckers to meet their deadlines and stay on schedule when it comes to picking up goods at ports.
The backlog has also caused a shortage of containers and the chassis needed to haul them. Containers wait for extended periods in ports, and it takes about twice as much time for operators to return the chassis, the Journal said.
A word on Oil Inflation (also man-made):
When the country went under the Biden Administration on January 20, 2021 Crude Oil was at about $54.00 – $55.00 per barrel. The first thing he did was to cancel the Keystone Pipeline and much of the new drilling contracts. The previous administration had us headed to Energy Independence and now we are headed down the path to Energy Dependence once again.
Today a barrel of oil costs about $85.31 – up about $30 per barrel in 10 months which would be an annualized inflation rate of 66.61%. Again, this is what I call Man-made Inflation.
We are now right back where we were in November 2014 when it comes to the price for a barrel of oil. Take a look at the following two charts.
ONE YEAR PRICE CHANGE …

TWENTY-ONE YEAR PRICE CHANGE …
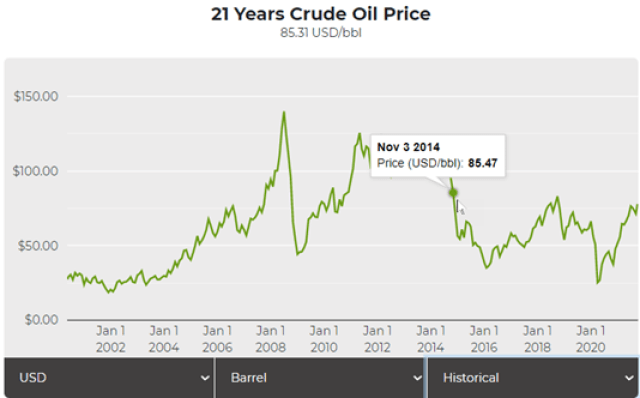
Notice how volatile oil can be when you look at 1 year versus 21 years of data.
Being an “old man” that lived through the days of the Jimmy Carter Presidency I used to thing that we would never, ever, have a worse leader of our country. I think now that I may have been wrong.
HOW SHOULD ONE INVEST WITH INFLATION ON THE HORIZON?
You will hear many on the radio, TV and other forms of media screaming to the top of their lungs, “Oh My God, inflation is on the way and you’d better put your money in Gold Bullion and Gold Currencies (Coins).” Some are even suggesting such things as Crypto-currencies.
Now I am not one that is against such investments … but I don’t think you should go overboard with them. In my opinion gold is more of a collectible than it is an investment, to many who acquire it. An investment is something that you attempt to buy at a low price and sell later at a high price.
Ask yourself, “How many people who invest in Gold Bullion or Coins actually sell it at some point later in life?” The answer is very few. Why is this? To me this is why I put gold in the same classification as Diamonds or Art Works for the common man. It is something we buy and hang on to and never get out of. We are proud to own it – and may even show it off from time to time like an old antique car … but seldom will be think of parting ways with it.
I recently had a dear friend who passed away who put all his investment capital into Gold and Silver Bullion for years. To my knowledge he never sold any of it and now it is up to his poor widow to determine what she should do with it. In all likelihood she will leave it to her kids who will leave it to their kids who will leave it to theirs, etc.
I remember telling my friend, more that once, that he would never be able to walk into a store in America and shave some gold off his gold bar to purchase goods or services. Sure, you can buy some things with gold – on the black market – but most of the things you can buy with gold would be illegal to own (Drugs, Machine Guns, etc.). If and when we get to the point that American stores and businesses are accepting Gold rather than cash … then many of us may as well strap on our side arms and meet up in places like Tombstone Arizona for a new shootout at the OK Corral.
The returns on gold have not been that great either – even through all the years of inflation – as compared to stocks … as I will show you in a moment.
While stocks do and can take a downturn at the outset of an inflationary period … it is not long before they recover – and each high is higher than the previous high when the stock market is rebounding. Remember, we have measured inflation since the early 1900s. We have also measured the stock market since before that.
In the charts that follow we will compare the Dow Jones Industrial Average to the price of gold and you will see in most periods, regardless of inflation, stocks come out the winner (not in all periods – but most). While the Dow Jones Industrial Average may not be the index of choice for many, I chose to use it here for two reasons: (a) it goes back to the turn of the century, and (b) in includes (today) the largest 30 public companies in America. Early on it only included the largest 12 public companies in America. Let’s turn back the hands of time and see how Gold has performed as compared to the Dow Jones Industrial Average (DJIA).
Looking back 5 years:

You can see here that a $10,000 investment in the DJIA would be worth about $20,000 today (up almost 100%) whereas a $10,000 investment in Gold would be worth about $14,000 today (up only about 40%).
Looking back 10 years:

Here a $10,000 investment would have grown to about $30,000 (up 200%) whereas Gold would be worth about the $10,000 you invested into it. In fact, you would have lost money from 2012 – 2020 … all while the stock market was growing. As for inflation, does most goods and services cost more today than they did in 2012? Answer: Many do!
Looking back 20 years:

Over the past 20 years we see that Gold clearly outperformed the DJIA – and this is what the gold pundits love to hang their hat on. Yes, Gold was up about 550% where the DJIA was only up about 300%. What the pundits do not tell you is the volatility you will have in a gold investment as inflation starts to lower. Look at the years 2012 to 2016. By the way, the darker grey areas of the charts are Recession Periods. In the recession of 2008-2009 both Gold and Stocks when lower before rebounding. In the recession of 2020 (caused mainly be the so-called Pandemic) stocks bounced higher as gold fell.
Here a $10,000 investment in Gold – if held for the entire period – would be worth about $65,000 whereas an investment of the same amount in the DJA would have returned you about $40,000. Of course, these numbers and the rest that have been used includes the original $10,000 invested.
What is not included in the stock is the DIVIDENDS that each of these companies pay and have paid over the years. This dividend can be used as current income or reinvested in the stock that pays it to purchase more shares. I’d venture to guess that if dividends were taken into account, then stock and gold would have been about tied over this period of time. Remember GOLD does not produce dividends or any form of cash flow.
Looking back 30 years:

If we go back 30 years and take a look, we see that the DJIA – through three major recessions – would have returned you about 1,000% making a $10,000 investment worth about $110,000 where as an investment in Gold would have given you about $50,000 for an investment of $10,000. Over 30 years the stock market more than doubled what gold could have done for you. Again, not even including the dividends.
If you are old enough to remember – in 1974 Richard Nixon resigned his presidency and Gerald Ford served out the remainder of his term to be followed by 4 years of the Jimmy Carter Administration. I bring this up since much in the news is comparing the Joe Biden Administration with the Jimmy Carter Administration.

During this period, as you will see in the next graph, the stock market was relatively flat and the gold market was on an uphill swing.
Then in 1981 Ronald Reagan was elected and changed the economy and the economic outlook of the country and he was followed by George H. W. Bush and Bill Clinton who continued to improve the economy.

Take a look what happened to gold vs. the stock market (DJIA) at this time:

So, over this 26-year period a $10,000 investment in gold would have netted you about $49,000 in value whereas the same investment in the stock market (assuming you had patience) would have netted you about $120,000 in value.
Now, let’s take a look at one more custom period from Gold’s hey days of the 80’s (when people and the news pundits really started to push it as an investment) to 2001.
1980 – 2001:

$10,000 in the DJIA would be worth about $140,000 in 2001. And $10,000 in gold would be worth less than $10,000 in 2001.
Now let’s pull it all together from 1900 – 2021:

Now consider this: $10,000 invested in the DJIA stocks in 1900 would be worth about $16,020,000 today whereas the same investment in Gold would be worth about $1,020,000 today. So, stocks, through all these years of Inflation and Deflation beat gold by 16 times.
So, how has inflation really effected the dollar and what is the best hedge?
The dollar had an average inflation rate of 2.92% per year between 1900 and today, producing a cumulative price increase of 3,165.60%. The 1900 inflation rate was 1.20%. The current year-over-year inflation rate (2020 to 2021) is now 5.39%.
This is perhaps why many Financial Advisors suggest their clients consider an inflation rate of 3% as they plan long-term for their financial well-being. There have been times that it has been worse and better. This table will show you some of those times by month from 1914 till now.
I have replicated the table for you on the next page (for those who don’t like to go on the internet to research). The years with inflation exceeding 10% are in yellow and those with inflation rates below 0% are in green.

Here are two more charts that shows what has happened to the US Dollar since 1900:
How $1.00 has declined in value over time …

We see here that $1.00 in 1900 is worth about 3¢ today.
How many dollars are needed today to purchase $1.00 worth of goods from 1900?

Today you would need $32.66 to purchase what $1.00 would have bought you in 1900. The point is that if the dollar has had a cumulative price increase of 3,165.60% since 1900 you will want an investment that has outperformed that.

$1.00 in the stock market in 1900 would give you $602 today … enough to purchase what $18.43 would buy in 1900. And $1.00 in gold would give you $102 today … enough to purchase $3.12 would buy in 1900. It appears that long-term both stocks and gold will offset inflation … but stocks tend to do it much better than gold does.
CONCLUSION:
So, the next time you hear some GURU – or worse yet – SOME HOLLYWOOD ENTERTAINER telling you to purchase gold to offset inflation (and put it in your IRA) … don’t bet the farm on it. Most of these people are doing it so that they can get more people involved in gold and drive the price of the bullion they own up in price (man-made inflation) … or they are gold brokers looking to make a commission.
There is nothing wrong with having a little gold in your overall investment portfolio, but rather than buying the bullion or the coins which you will hold to infinity and never sell, consider instead, an Exchange Traded Fund (ETF) that holds gold bullion for you in its portfolio. Here’s how this fund has performed since being tracked:

As you can see this fund started on 11/15/2004 and has grown from $44.43 per share to $167.63 per share. Each share represents about 1/10 ounce of gold which is trading at about $1,676.30 per ounce now. If you calculate the compounded average rate of return since inception (through all the ups and downs) this would be about 8.12% per year and can be seen as follows:

So, yes, consider some gold to offset losses a stock portfolio my incur during down periods with high inflation … but don’t sell all your stocks and buy gold with all the proceeds. A wise man once told me, “When it comes to the stock market, time in the market is more important and more lucrative than trying to time the market.”
In the graph that follows, the green line represents the return of the price (only – no dividends) of DIA – the ETF that tracks the Dow Jones Industrial Average; and the yellow line represents GLD – the ETF that tracks the price of Gold Bullion.

Notice that even though the stock market was headed down in September 2021 due to “fears of inflation” so was the gold market. When things turned in October 2021 the stock market started to head up along with the gold market … but in the end … the stock market has returned about 1.20% since September 1st and the Gold market is down slightly more than 2%. That’s a difference of 3% in favor of the stock market.
I leave you with this to ponder:
Do not fear inflation when it comes to you stock investments!